|
Jana Zeller Hi! I'm an ELLIS PhD student at the ETH Max Planck Center for Learning Systems, where I'm fortunate to be supervised by Wieland Brendel and Ryan Cotterell. Previously, I earned my M.Sc. in Advanced Computer Science from Oxford, supported by a Google DeepMind Scholarship. Before that, I completed my Bachelor at Karlsruhe Institute of Technology. where I worked with Luca Torresi and Pascal Friederich on chemical property prediction. I also spent an exciting summer at Carnegie Mellon University as part of the Robotics Institute Summer Scholars program, exploring efficient architectures for videos with Jonathon Luiten and Deva Ramanan. Besides research, I enjoy theatre, board games, and baking 🧁 (I am always happy to trade baking recipes and on the hunt for somebody to play set with :D ) |

|
ResearchI'm interested in computer vision, natural language processing, and how we can combine both to build more intelligent systems, that can reason and navigate about the world in mutliple modalities. |
|
MentisOculi: Revealing the Limits of Reasoning with Mental Imagery
Jana Zeller, Thaddäus Wiedemer, Fanfei Li, Thomas Klein, Prasanna Mayilvahanan, Matthias Bethge, Felix Wichmann, Ryan Cotterell, Wieland Brendel Under Review project page / arXiv / code Can models reason better with intermediate visualizations, akin to human mental imagery? MentisOculi evaluates this across frontier models and finds that visual thoughts do not yet improve reasoning.
|

|
Highlight: Learning Visual Prompts for Vision-Language Models
Jana Zeller, Aleksandar (Suny) Shtedritski, Christian Rupprecht, CVPR (Emergent Visual Abilities and Limits of Foundation Models), 2025 project page / code We automatically discover visual prompts for CLIP. Interestingly, they look like red circles.
|
|
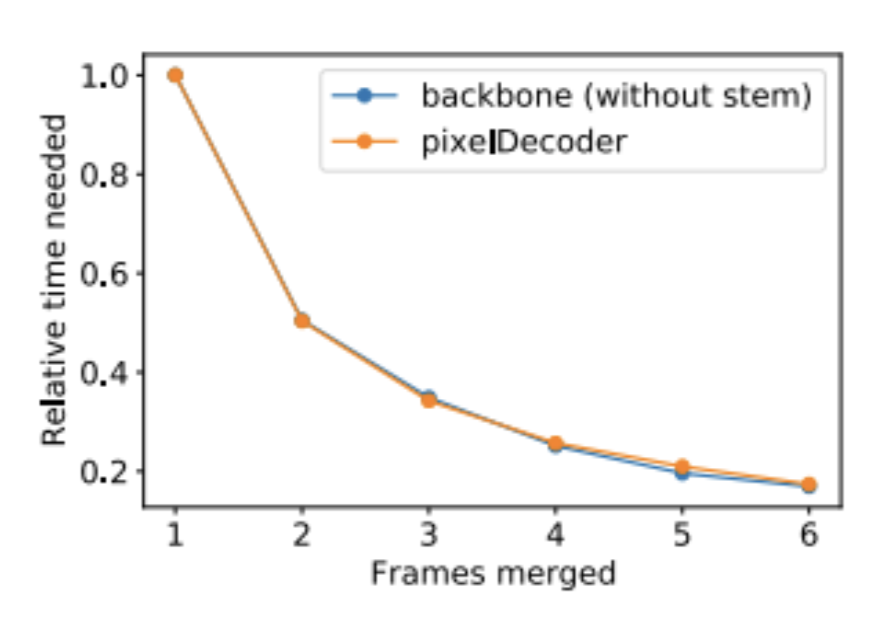
Treating Video as an Image
Jana Zeller, Deva Ramanan, Jonathon Luiten Preprint, 2022 preprint / poster / video We speedup video processing by merging frames together and passing them through the same vision model only once.
|
|
This website template is borrowed from Jon Barron. Thanks! |